
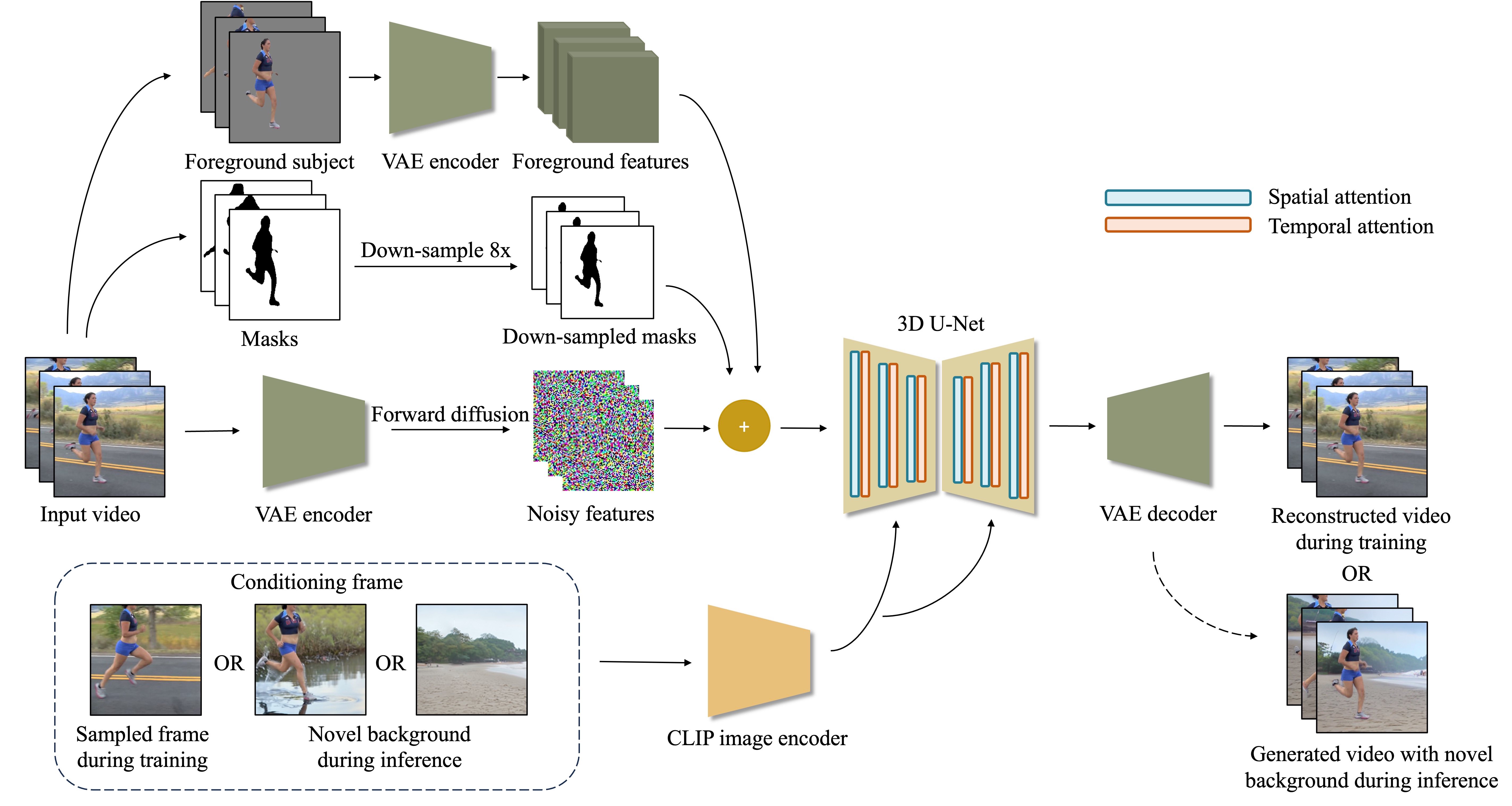
Video background generation with composited frame conditioning
|
Original video
(not used as model input) |
Segmentation
|

Mallard wandering around a firepit.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|
A man folding bed sheets.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

Purple tie-dye jogger runs in serene park, mist over lake.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

A woman is water-skiing.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

A woman riding a horse.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

A dog plays beside an old man.
Condition
|
Output
|
|---|
Video background generation with background-only frame conditioning
|
Original video
(not used as model input) |
Segmentation
|

Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

Condition
|
Output
|
|---|
Diverse generated camera motion
|
Segmentation
|

Lost in thought, figure strolls through foggy cityscape in winter attire.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
Seed 4
|
|---|
|
Segmentation
|

A woman riding a motorcycle in a city.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
Seed 4
|
|---|
|
Segmentation
|

Infant in blue onesie explores a toy-filled nursery.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
Seed 4
|
|---|
|
Segmentation
|

Child in blue jacket joyfully picks a pumpkin in autumn patch.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
|---|
|
Segmentation
|

Traveler, backpack in tow, seeks secrets in desolate landscape's vastness.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
|---|
|
Segmentation
|

Immersed gamer moves intensely in high-tech room, exploring virtual reality.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
|---|
Different backgrounds with the same foreground
Woman in red faces vast grey, reflecting an inner journey
|
Original video
|
Segmentation
|

Condition 1
|
Output 1
|

Condition 2
|
Output 2
|

Condition 3
|
Output 3
|

Condition 4
|
Output 4
|

Condition 5
|
Output 5
|

Condition 6
|
Output 6
|

Condition 7
|
Output 7
|
|---|
Woman poised backstage, ready for defining theater spotlight moment.
|
Original video
|
Segmentation
|

Condition 1
|
Output 1
|

Condition 2
|
Output 2
|

Condition 3
|
Output 3
|

Condition 4
|
Output 4
|
|---|
Determined athlete runs through cool, overcast weather, undeterred in the morning.
|
Original video
|
Segmentation
|

Condition 1
|
Output 1
|

Condition 2
|
Output 2
|

Condition 3
|
Output 3
|
|---|
A determined athlete trains in diverse landscapes for marathon endurance.
|
Original video
|
Segmentation
|

Condition 1
|
Output 1
|

Condition 2
|
Output 2
|
|---|
Woman confidently at outdoor, engaging at sunset.
|
Original video
|
Segmentation
|

Condition 1
|
Output 1
|

Condition 2
|
Output 2
|

Condition 3
|
Output 3
|

Condition 4
|
Output 4
|
|---|
Diverse generated contents
|
Segmentation
|

Traveler, backpack in tow, seeks secrets in desolate landscape's vastness.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
Seed 4
|
|---|
|
Segmentation
|

A child creating shimmering soap bubbles at a grassland.
Condition
|
Seed 1
|
Seed 2
|
Seed 3
|
Seed 4
|
|---|
|
Segmentation
|

Child in beach attire joyfully runs shore, bucket in hand, playing.
Condition
|
Seed 1
|
Seed 2
|
|---|
Condition frame of a different subject
|
Original video
(not used as model input) |
Segmentation
|

A man is holding a balloon, and floating up by the balloon.
Condition
|
Output
|
|---|
|
Original video
(not used as model input) |
Segmentation
|

Cyclist pauses, admires scenic overlook with open road and tranquil landscape.
Condition
|
Output
|
|---|
Comparison with baselines
Here we show the video version of Fig. 4 in the paper.
A car drifting on a snowy mountain road
|
Original video
|
Segmentation
|

Condition
|
|---|---|---|
|
Ours
|
Gen1 [9]
|
Text2LIVE [3]
|
|
TokenFlow [12]
|
Control-A-Video [7]
|
|
|
AnimateDiff [13]
|
VideoCrafter1 [6]
|
A woman performing motorcycle stunts
|
Original video
|
Segmentation
|

Condition
|
|---|---|---|
|
Ours
|
Gen1 [9]
|
Text2LIVE [3]
|
|
TokenFlow [12]
|
Control-A-Video [7]
|
|
|
AnimateDiff [13]
|
VideoCrafter1 [6]
|